|
JoonHo (Brian) Lee I'm a visting scholar at ARPL Lab in UC Berkeley, where I am working on world models and distributed perception. I'm interested in building world models for robots to physically understand the world as we do. My previous research include LiDAR perception and traversability estimation for off-road autonomous navigation. I received my Master's from the University of Washington, where I was advised by Byron Boots. |

|
Research |

|
ICRA, 2024 arXiv / code |
||
|
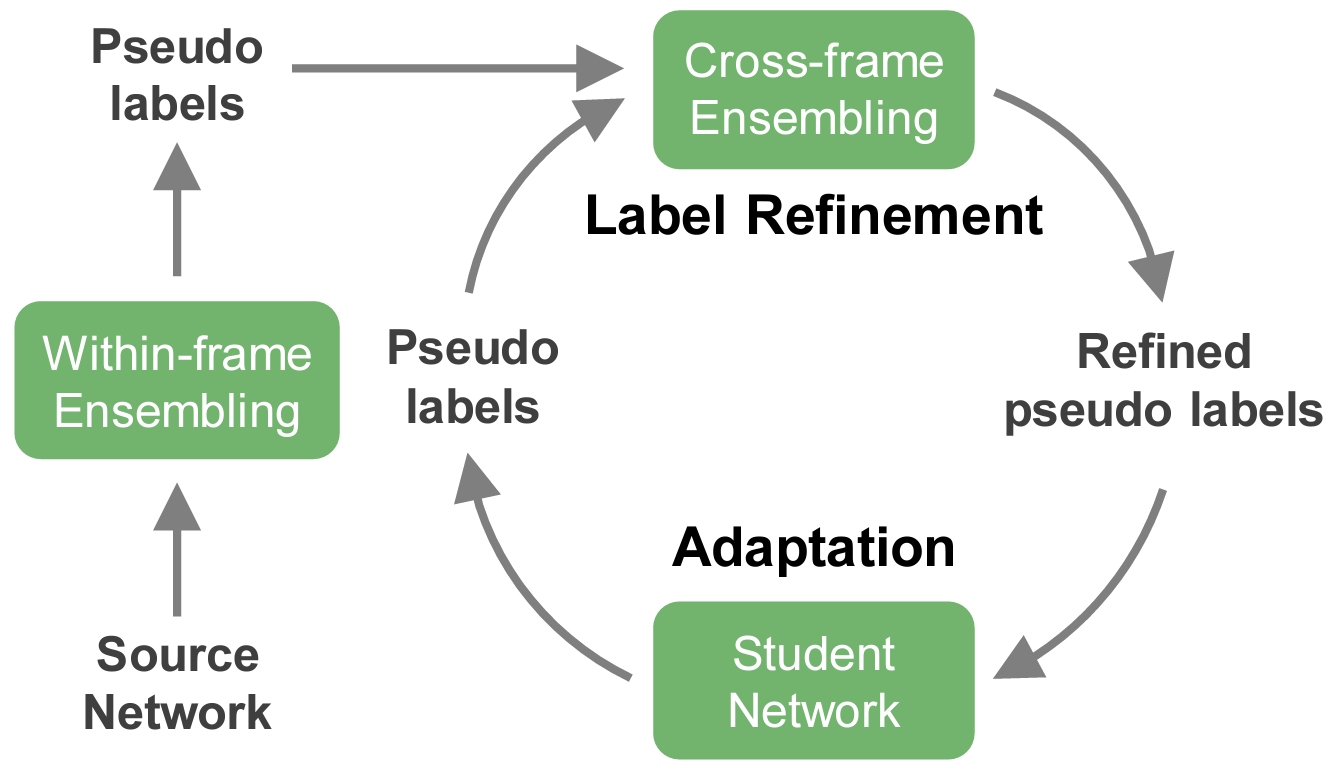
ICCV, 2023 Oral Presentation (<1.8%) arXiv / code |
||

|
RSS, 2023 arXiv / code |
||

|
|
||
|
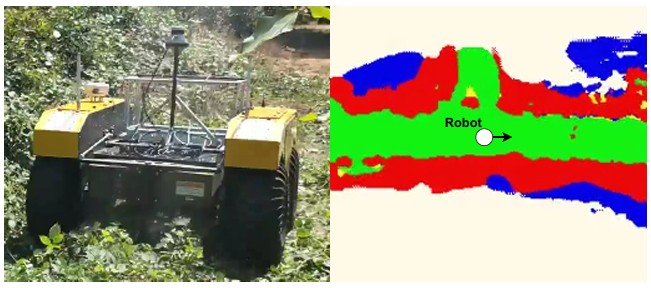
CoRL, 2022 arXiv / code |
||

|
|
||
Miscellanea |
Tech Reports | |

|
preprint, 2025 arXiv / code |